近年来,凭借颠覆性的技术理念,专注于保护数据隐私的联邦学习备受业界关注。今日,同盾科技人工智能研究院团队在院长、佛罗里达大学终身教授李晓林带领下,推出了《知识联邦白皮书》。
据介绍,知识联邦是同盾提出的国产原创、自主可控、国际领先的技术体系,该体系在解决了数据割裂和隐私保护问题的同时,可以进一步开展跨源跨域的知识发现、表示、归纳、推理和演绎。同盾同时开发了知识联邦的参考实现平台:智邦平台,已经进化到了2.1版。
白皮书中对知识联邦的背景、定义、平台、挑战、场景应用以及未来发展前景进行了全方位、全景式剖析,并对人工智能3.0时代进行展望。
延伸阅读
什么是知识联邦?
知识联邦是将散落在不同机构或个人的数据联合起来转换成有价值的知识,同时在联合过程中采用安全协议来保护数据隐私。知识联邦不是一种单一的技术方法,它是一套理论框架体系,是人工智能、大数据、密码学等几个领域交叉融合的产物。
知识联邦和联邦学习是一个概念吗?
联邦学习是知识联邦的一个子集,专注于数据分布的联合建模。而知识联邦关注的是安全的、数据到知识的“全生命周期”的知识创造、管理和使用及其监管,设计目标是面向生产环境的完整知识联邦生态系统,致力于推动下一代人工智能,而不仅仅是一个安全的联合建模。
知识联邦为何而生?
数据、算法和算力三要素构成了人工智能2.0世界的基础设施,现实世界中,人工智能所需的数据,大多都会以“数据孤岛”的方式分布。
而与此同时,数据也正式被中央认定为新型生产要素,这势必会对隐私与安全提出更高、更严格的规范。
无论是隐私、数据泄露的问题,还是可能引发的数据垄断问题,其症结都在于传统深度学习下数据的集中处理模式。
一大批专家学者决定另辟蹊径,知识联邦的概念也因此应运而生。
知识联邦的本质是什么?
知识联邦是基于多方数据进行安全的知识共创、共享和推理,其本质就是打造安全的人工智能,实现数据可用不可见。知识联邦能够实现各地区各部门间数据共享交换,推进多方数据协作和开放共享;知识联邦在整合各方数据资源的同时可以保护数据安全,尤其关注对政务数据和个人数据等敏感数据的保护。知识联邦的最终目的是为了提升社会数据资源价值,培育数据协作新模式,并为数字经济新产业提供技术支撑。
知识联邦带来哪些革新?
简单来讲,知识联邦连通了每个数据孤岛所属的机构——“数据邦国”,“数据邦国” 是一个个独立的政治单元,他们自行管理自己的数据,拥有无可辩驳的“数据主权”。机构之间会通过一种协议联合起来,共同参与组成一个整体作为联邦机构,所有参与成员共同赋予联邦机构一定的权利由其统一行使。
其主要优势是:
1、全样本触达。联邦后机构间的数据是分而治之,各自为数据所有者控制,每个节点上的数据相对只是小数据,但是由于可以触达更多的数据,其性能甚至会超越维度有限数据的中心化聚集方式。
2、数据不动模型动。联邦后的原始数据保留在本地,计算和学习也发生在本地,中心节点仅对参与方模型知识进行安全的聚集。弱中心化模式达成了效率和安全之间的平衡,这种模式尤其适合在强监管行业应用,有助于监管部门开展合规监管工作。
知识联邦有哪些应用场景?
知识联邦管理知识安全联邦的全生命周期,为打造安全的知识融合、管理、使用的生态系统提供设计指南和标准。它支持安全多方共享、安全多方计算、安全多方学习、安全多方预测、安全多方推理等应用,可以用于涉及到数据安全和隐私保护诸多领域。尤其是在金融、医疗或政务等行业中应用知识联邦,可以加快智慧金融、智慧医疗、智慧政务、智慧城市等领域的建设发展。
知识联邦的分类可以有很多种方式,可以按联邦阶段、数据特点、参与对象类型和应用目的进行划分。
知识联邦当下遇到哪些新挑战?
纵观技术的发展史,新技术的产生往往可以解决很多旧矛盾,但与此同时,它也势必带来新的问题,知识联邦也难逃此定律。事实上,知识联邦作为新兴技术仍有很多来自技术、规则和法律等方面的挑战。
比如,如何选择可信的第三方,制定令各方都满意的协调和监管机制、怎么样鼓励数据拥有方持续参与到联邦建模里面来、如何保证联邦过程中各机构间的公平性、如何分配包括平台运营方、平台提供方、模型设计者等各方利润等等问题?
要彻底解决这些问题,我们恐怕还需要投入很多新的努力。
知识联邦将会为人工智能发展带来什么?
纵览人工智能发展史,能观察到两个现象:人工智能与计算平台的发展阶段有相当的巧合。各个阶段的飞跃间隔大约30年,由此推测在2040年左右人们将会迎来人工智能3.0时代。
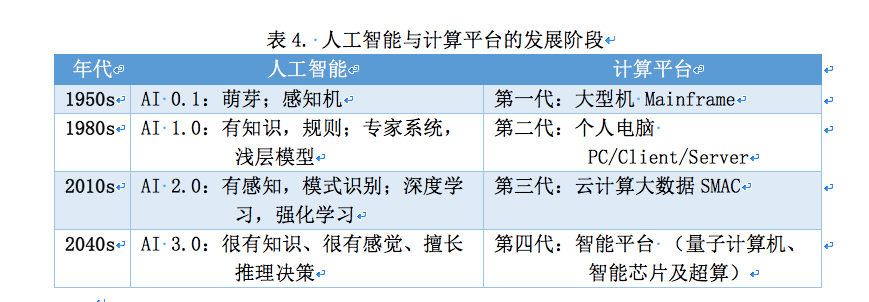
知识联邦倡导统一的多层次的安全联邦,从信息层、模型层、认知层到知识层。人工智能3.0时代也必须解决数据安全、个人隐私以及社会安全、人类安全等核心问题。知识联邦的安全人工智能生态系统为人工智能3.0时代奠定了坚实的基石。
(责编:吕骞、赵竹青)
